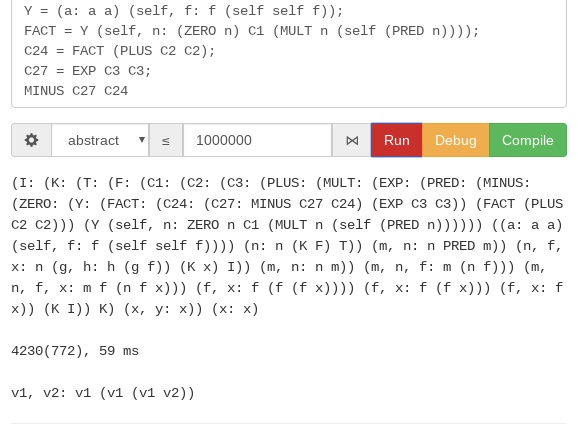
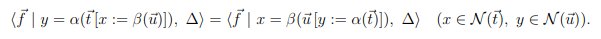Сделано все, кроме гомотопических прититивов <> @ []. Вернулись на позапрошлогодний уровень EXE. Пришлось сделать case аналисис в стиле ML языков (с палками), так как, говорят 2D синтаксис голым эрланговским LALR не возьмешь. С where тоже проблемы, пришлось делать карированую версию where. Оно и логично — в минималистичных ядрах должно быть все карированое. YECC файл занимает ровно 50 строчек, в отличие от 261 строки для EXE. В примере показан Хрономирфизм и Категорная Семантика односвязного списка
module lam1 where
listCategory (A: U) (o: listObject A): U = undefined
histo (A:U) (F: U -> U) (X: functor F) (f: F (cofree F A) -> A) (z: fix F): A
= extract A F ((cata (cofree F A) F X (\(x: F (cofree F A)) -> CoFree (Fix (CoBindF (f x) ((X.1 (cofree F A) (fix (cofreeF F A)) (uncofree A F) x)))))) z) where
extract (A: U) (F: U -> U): cofree F A -> A = split
| CoFree f -> unpack_fix f where
unpack_fix: fix (cofreeF F A) -> A = split
| Fix f -> unpack_cofree f where
unpack_cofree: cofreeF F A (fix (cofreeF F A)) -> A = split
| CoBindF a -> a
futu (A: U) (F: U -> U) (X: functor F) (f: A -> F (free F A)) (a: A): fix F
= Fix (X.1 (free F A) (fix F) (\(z: free F A) -> w z) (f a)) where
w: free F A -> fix F = split
| Free x -> unpack x where
unpack_free: freeF F A (fix (freeF F A)) -> fix F = split
| ReturnF x -> futu A F X f x
| BindF g -> Fix (X.1 (fix (freeF F A)) (fix F) (\(x: fix (freeF F A)) -> w (Free x)) g) where
unpack: fix (freeF F A) -> fix F = split
| Fix x -> unpack_free x
chrono (A B: U) (F: U -> U) (X: functor F)
(f: F (cofree F B) -> B)
(g: A -> F (free F A))
(a: A): B = histo B F X f (futu A F X g a)
listAlg (A : U) : U
= (X: U)
* (nil: X)
* (cons: A -> X -> X)
* Unit
listMor (A: U) (x1 x2: listAlg A) : U
= (map: x1.1 -> x2.1)
* (mapNil: Path x2.1 (map (x1.2.1)) (x2.2.1))
* (mapCons: (a:A) (x: x1.1) -> Path x2.1 (map (x1.2.2.1 a x)) (x2.2.2.1 a (map x)))
* Unit
listObject (A: U) : U
= (point: (x: listAlg A) -> x.1)
* (map: (x1 x2: listAlg A)
(m: listMor A x1 x2) ->
Path x2.1 (m.1 (point x1)) (point x2))
* Unit
{module,{id,1,"lam1"},
{where,1},
[],
[{def,{id,5,"listCategory"},
{tele,[{id,5,"A"}],
{id,5,"U"},
{tele,[{id,5,"o"}],{app,{id,5,"listObject"},{id,5,"A"}},[]}},
{id,5,"U"},
{id,5,"undefined"}},
{def,{id,7,"histo"},
{tele,[{id,7,"A"}],
{id,7,"U"},
{tele,[{id,7,"F"}],
{pi,{id,7,"U"},{id,7,"U"}},
{tele,[{id,7,"X"}],
{app,{id,7,"functor"},{id,7,"F"}},
{tele,[{id,7,[...]}],
{pi,{app,...},{...}},
{tele,[...],...}}}}},
{id,7,"A"},
{app,{app,{app,{id,8,"extract"},{id,8,"A"}},{id,8,"F"}},
{app,{app,{app,{app,{app,{id,8,[...]},{app,{...},...}},
{id,8,"F"}},
{id,8,"X"}},
{app,{lam,{tele,[{id,...}],{app,...},[]},{id,8,[...]}},
{app,{id,8,[...]},{app,{...},...}}}},
{id,8,"z"}}},
{def,{id,9,"extract"},
{tele,[{id,9,"A"}],
{id,9,"U"},
{tele,[{id,9,"F"}],{pi,{id,9,[...]},{id,9,...}},[]}},
{pi,{app,{app,{id,9,"cofree"},{id,9,"F"}},{id,9,"A"}},
{id,9,"A"}},
{split,[{br,[{id,10,"CoFree"},{id,10,[...]}],
{app,{id,10,...},{id,...}}}]},
{def,{id,11,"unpack_fix"},
[],
{pi,{app,{id,...},{...}},{id,11,...}},
{split,[{br,...}]},
{def,{id,...},[],...}}}},
{def,{id,16,"futu"},
{tele,[{id,16,"A"}],
{id,16,"U"},
{tele,[{id,16,"F"}],
{pi,{id,16,"U"},{id,16,"U"}},
{tele,[{id,16,"X"}],
{app,{id,16,"functor"},{id,16,[...]}},
{tele,[{id,16,...}],{app,{...},...},{tele,...}}}}},
{app,{id,16,"fix"},{id,16,"F"}},
{app,{id,17,"Fix"},
{app,{app,{app,{app,{fst,{id,17,...}},{app,{app,...},{...}}},
{app,{id,17,[...]},{id,17,...}}},
{lam,{tele,[{id,17,...}],{app,{...},...},[]},
{app,{id,17,...},{id,...}}}},
{app,{id,17,"f"},{id,17,"a"}}}},
{def,{id,18,"w"},
[],
{pi,{app,{app,{id,18,"free"},{id,18,[...]}},{id,18,"A"}},
{app,{id,18,"fix"},{id,18,"F"}}},
{split,[{br,[{id,19,[...]},{id,19,...}],
{app,{id,...},{...}}}]},
{def,{id,20,"unpack_free"},
[],
{pi,{app,{...},...},{app,...}},
{app,{split,...},{...}},
{def,{...},...}}}},
{def,{id,26,"chrono"},
{tele,[{id,26,"B"},{id,26,"A"}],
{id,26,"U"},
{tele,[{id,26,"F"}],
{pi,{id,26,"U"},{id,26,"U"}},
{tele,[{id,26,"X"}],
{app,{id,26,[...]},{id,26,...}},
{tele,[{id,...}],{pi,...},{...}}}}},
{id,29,"B"},
{app,{app,{app,{app,{app,{id,29,"histo"},{id,29,[...]}},
{id,29,"F"}},
{id,29,"X"}},
{id,29,"f"}},
{app,{app,{app,{app,{app,{id,...},{...}},{id,29,...}},
{id,29,"X"}},
{id,29,"g"}},
{id,29,"a"}}}},
{def,{id,31,"listAlg"},
{tele,[{id,31,"A"}],{id,31,"U"},[]},
{id,31,"U"},
{sigma,{tele,[{id,32,"X"}],{id,32,"U"},[]},
{sigma,{tele,[{id,33,"nil"}],{id,33,"X"},[]},
{sigma,{tele,[{id,34,...}],{pi,{...},...},[]},
{id,35,"Unit"}}}}},
{def,{id,37,"listMor"},
{tele,[{id,37,"A"}],
{id,37,"U"},
{tele,[{id,37,"x2"},{id,37,"x1"}],
{app,{id,37,"listAlg"},{id,37,"A"}},
[]}},
{id,37,"U"},
{sigma,{tele,[{id,38,"map"}],
{pi,{fst,{id,38,[...]}},{fst,{id,38,...}}},
[]},
{sigma,{tele,[{id,39,"mapNil"}],
{app,{app,{...},...},{fst,...}},
[]},
{sigma,{tele,[{id,...}],{app,...},[]},{id,41,[...]}}}}},
{def,{id,43,"listObject"},
{tele,[{id,43,"A"}],{id,43,"U"},[]},
{id,43,"U"},
{sigma,{tele,[{id,44,"point"}],
{pi,{tele,[{id,...}],{app,...},[]},{fst,{id,...}}},
[]},
{sigma,{tele,[{id,45,[...]}],{app,{app,...},{...}},[]},
{id,48,"Unit"}}}}]}
В тред приглашаются специалисты по LALR парсерам.
_______________
[1].
https://github.com/groupoid/infinity/blob/master/src/cub_parser.yrl