Лисп — абстракции на стероидахВиталий Маяцких |
I know God had six days to work, So he wrote it all in Lisp. Eternal Flame (song parody)
Аннотация: Существует расхожее мнение о невысокой скорости работы языка Common Lisp. В данной статье автор попытается развенчать этот миф.
Article tries to debunk the widespread myth of Common Lisp slowness, providing numerous illustrations to the contrary.
Обсуждение статьи ведётся по адресу
http://community.livejournal.com/fprog/7453.html.
1 Лисп — медленный?
Почему Лисп должен быть медленным? Для этого есть несколько вполне обоснованных причин:
- Лисп — динамический язык, для которого, как известно, нельзя сгенерировать быстрый машинный код, эквивалентный коду на C. Динамичность языка требует существенных накладных расходов при исполнении программы, как то: необходимость постоянной проверки типов аргументов функций, преобразование данных из внутреннего представления в машинное и обратно (т. н. boxing/unboxing), автоматическое управление памятью и т. п.
- Лисп, при всей простоте синтаксиса, является очень мощным языком, для которого в принципе написать эффективный компилятор весьма сложно. Макросы, функции высших порядков и обобщённые функции, система рестартов, интроспекция, метаобъектный протокол, доступный во время исполнения компилятор с возможностью на ходу переопределять код (в некоторых случаях и код самого компилятора!) — ну как тут разогнаться?
- Маргинальность и малая распространённость Лиспа не привлекает крупных разработчиков ПО (например, Microsoft), которые могли бы реализовать хороший компилятор и постоянно его поддерживать. Любители из числа увлечённых студентов, научных работников и профессионалов высокого класса не могут на постоянной основе уделять достаточно времени для эффективного развития компилятора.
Практическим подтверждением этих постулатов является знаменитый «The Computer Language Benchmarks Game»1. Действительно, если сравнить какую-либо реализацию Scheme2 с GNU/gcc, то проигрыш Лиспа практически по всем пунктам составляет десятки, а то и сотни раз. Получается, что при всей своей разрекламированной элитарности, затрачивать усилия и время на изучения Лиспа не стоит, т. к. когда дело дойдёт до реального, «боевого» применения в более-менее критичном к ресурсам проекте, то в сто раз более медленная программа заказчика не устроит, даже если она будет представлять собой образец программистского искусства?
В действительности, дела обстоят не так плохо. Отложим пока вопрос распространённости языка, наличия популярных библиотек, а также размера и качества сообщества, сформировавшегося вокруг языка (адекватность «The Computer Language Benchmarks Game» тоже вызывает многочисленные сомнения).
1.1 Современные реализации
Лисп — очень старый язык. Появившись на заре вычислительной техники примерно в одно время со своим антагонистом — Фортраном, Лисп за прошедшие 50 лет не только выжил, но и стал значительно мощнее и гибче первых набросков его автора, Джона МакКарти. Например, Лисп обзавёлся чрезвычайно мощной, уникальной системой макросов, а также первой в мире официально стандартизованной объектной системой — CLOS. Особая структура программ на Лиспе и требования к среде времени исполнения привели даже к тому, что были разработаны специальные Лисп-машины, аппаратно ускоряющие многие специфичные примитивы языка.
Однако, время Лисп-машин ушло, рост популярности языка Си сказался на современных машинных архитектурах, и многие интересные возможности оказались за бортом мейнстрима. В условиях довольно скудной, хотя и производительной аппаратной базы, написать компилятор, эффективно преобразующий программу с языка сверхвысокого уровня в примитивный машинный код, стало ещё сложнее. Тем не менее, появились коммерческие компиляторы Лиспа, такие, как Allegro и LispWorks, успешно существующие уже более двух десятков лет.
Академическая среда также не осталась в стороне: в университете Карнеги– Меллона в начале 80-х годов начал развиваться весьма удачный проект CMUCL. Отличительной чертой CMUCL является наличие эффективного компилятора в машинный код для множества аппаратных платформ. Впоследствии на базе CMUCL были созданы коммерческий компилятор Scieneer Common Lisp и открытый компилятор Steel Bank Common Lisp.
Существует множество других реализаций, например, CLISP, Clozure CL, GCL, ABCL, не говоря о многочисленных реализациях более простого языка Scheme или совсем специфичных лиспоподобных языков.
Многие реализации либо занимаются трансляцией кода на Lisp в код на языке C с последующей сборкой в обычной инфраструктуре, либо используют компиляцию в байт-код для встроенной виртуальной машины. Оба подхода не оптимальны с точки зрения эффективности выполнения готового кода.
В первом случае промежуточным представлением является код на другом языке, механически сгенерированный по шаблонам, и поэтому выглядящий несколько инородно и избыточно. По такому коду компилятор Си, как правило, не может сгенерировать эффективный машинный код. К тому же, полностью теряется метаинформация о структуре лисповой программы после её предварительного разбора. Эту информацию можно было бы использовать на стадии генерации машинного кода, но до сишного компилятора она не доходит, и возможность оптимизации теряется.
Второй подход (виртуальная машина) плох тем, что интерпретация виртуального кода существенно медленнее, чем исполнение программы на «родном» для процессора языке. Конечно, существуют техники вроде JIT, когда байт-код предварительно компилируется в машинный код, но возникает та же проблема, что и в первом случае: цепочка «исходный код — машинный код» оказывается разорванной, и многие преобразования и оптимизации сделать оказывается уже невозможно.
Гораздо лучше эффективность у компиляторов, осуществляющих всю работу собственными силами. На текущий момент, вероятно, самым мощным из них является, как ни странно, свободный SBCL (к слову о силе свободного сообщества). Именно о нём и пойдёт в дальнейшем речь, как о наилучшем представителе семейства Common Lisp.
1.2 Steel Bank Common Lisp
Начав свой славный путь как попытку более логичной реорганизации исходного кода CMUCL, SBCL перехватил пальму первенства у своего родича в плане активности разработки компилятора. На данный момент Linux-порт SBCL поддерживает процессоры Intel x86 и x86-64, PowerPC, Sparc, Alpha и MIPS. Ведутся работы по переносу компилятора на архитектуру ARM. Существуют также порты для других операционных систем, таких как Mac OS X, *BSD и Windows, но с меньшей степенью поддержки. SBCL полностью соответствует стандарту ANSI Common Lisp, обладает одной из лучших реализаций метаобъектного протокола MOP (движущая сила объектной системы CLOS), широко поддерживается библиотеками, а также имеет обширное сообщество разработчиков и пользователей. Не последним по значимости фактором является весьма детальная поддержка техник оптимизаций для процессоров x86 и, особенно, для x86-64. Например, по умолчанию используются команды условной загрузки CMOV, косвенная адресация относительно точки исполнения (RIP-relative), а для операций с числами в формате single и double используется векторное расширение SSE2. На машинах с большим количеством регистров SBCL минимизирует операции с памятью, размещая в них часто используемую служебную информацию.
SBCL является двухпроходным компилятором. На первом этапе исходная
программа трансформируется в форму ICR (Implicit Continuation
Representation), которая представляет собой граф вычислений. В
полученном графе проводятся все высокоуровневые преобразования:
раскрытие макросов, частичное вычисление (вместо (+ 2 2)
компилятор вставит сразу 4), поиск и замена знакомых компилятору
паттернов на более эффективные конструкции, устранение «мёртвого»
кода. Важным шагом является вывод типов, что во многом и
обуславливает превосходство SBCL в скорости над другими
реализациями. Конечно, не везде в динамическом языке можно вывести
типы. Да и там, где можно, компилятор иногда ошибается. Но факт налицо:
SBCL автоматически выводит типы и оптимизирует код в
соответствии с ними. Все стадии оптимизации выполняются в цикле до тех
пор, пока между соседними итерациями не перестанут появляться
изменения в графе (внутреннем представлении компилируемой программы).
На втором этапе подготовленный граф конвертируется в набор виртуальных операций VOP, которые представляют собой блоки кода, написанного на смеси Лиспа и ассемблера, встроенного в SBCL. Этот код выполняет какую-либо характерную операцию: например, преобразование числа из внутреннего представления в машинный, сложение двух чисел типа complex и т. п. Для каждого типа процессора в SBCL реализован свой набор VOP. Компилятору доступны свойства VOP, такие, как виртуальная «стоимость» исполнения данной операции, количество и типы аргументов, задействованные машинные регистры, условия исполнения и т. д. Основываясь на этих данных, компилятор комбинирует виртуальные операции, стараясь сгенерировать максимально быстрый код. На этом этапе происходит устранение лишнего копирования значений, оптимизация загрузки регистров, а также частичная реорганизация кода для оптимальной загрузки конвейеров процессора.
Финальной стадией является непосредственно генерация машинного кода и разрешение адресов переменных, точек перехода и т. д.
Как видно, в SBCL реализованы практически все оптимизации, доступные в других компиляторах. Всё это позволяет генерировать машинный код, приближающийся по эффективности к коду на C. Однако, для многих частных случаев в SBCL не описана трансформация, либо из-за ошибки в логике выбирается не самый оптимальный вариант. Поэтому для написания оптимальных по производительности лисповых программ очень желательно хотя бы уметь читать ассемблерный код процессора, для которого пишется программа. Стоит отметить, что это одинаково верно и для всех остальных языков, т. к. профайлер — другое доступное средство для понимания программы во время её исполнения, показывает только как работает программа, но не почему. Иной раз, гораздо быстрее дизассемблировать функцию и посмотреть, что именно сделал компилятор, чем гадать с перебором множества вариантов. Конечно, достаточно хорошее знание ассемблера в наше время — умение редкое, поэтому SBCL в процессе компиляции старательно выдаёт на экран сообщения, в которых предупреждает о неоптимально сгенерированном коде, с аргументацией, почему он так сделал. Устранив недостатки в исходном коде, можно получить значительно более компактный и быстрый машинный код.
В крайнем случае, когда на каком-то участке программы нужна максимальная производительность, имеет смысл воспользоваться интерфейсом для подключения внешних модулей, написанных, например, на языке Си. Такое подключение делается действительно очень просто при помощи библиотеки CFFI. Но обычно хватает и производительности лиспового кода, в чём мы ещё убедимся.
1.3 Как оптимизировать программу
Рассмотрим на очень простом коротком примере, на что способен
SBCL. Определим функцию sum для сложения двух чисел:
Компилятор ничего не знает о типах аргументов, потому что функция в
динамическом языке может получить на вход аргументы любого типа. Если
с помощью стандартной лисповой функции disassemble посмотреть
на результат, то сразу становится понятно, что быстро наше сложение
работать не будет:
; disassembly for SUM ; 02D59DFD: 488B55F8 MOV RDX, [RBP-8] ; no-arg-parsing entry point ; E01: 488B7DF0 MOV RDI, [RBP-16] ; E05: 4C8D1C25E0010020 LEA R11, [\#x200001E0] ; GENERIC-+ ; E0D: 41FFD3 CALL R11 ; E10: 480F42E3 CMOVB RSP, RBX ; E14: 488BE5 MOV RSP, RBP ; E17: F8 CLC ; E18: 5D POP RBP ; E19: C3 RET
В первых трех инструкциях компилятор передаёт аргументы в функцию GENERIC-+,
которая для данных аргументов определяет наиболее подходящую
специализированную функцию сложения. (Последние четыре инструкции — это
восстановление предыдущего фрейма локальных переменных, и
непосредственно к коду логики функции не относятся).
Допустим, мы знаем, что складывать этой функцией придётся только целые значения. Сделаем соответствующую подсказку компилятору, объявив типы:
Здесь мы указываем компилятору типы переменных a
и b. Для типа FIXNUM по стандарту
компилятор должен использовать наиболее
эффективную форму представления числа для данной аппаратной архитектуры. Для процессора это,
естественно, будет обычное целое число, загружаемое непосредственно в
регистр. Но в Лиспе программисту такой тип данных недоступен,
потому что любая сущность в динамическом языке — это объект, который
нужно уметь идентифицировать и обрабатывать соответствующим образом. Поэтому в
SBCL для типа FIXNUM несколько младших битов машинного слова
отдано под служебную информацию, и при машинных операциях
над FIXNUM нужно эти служебные биты убирать и потом
восстанавливать. Тем не менее, код этого варианта функции получился
гораздо лучше:
; disassembly for SUM ; 02DC6B43: 488BC1 MOV RAX, RCX ; no-arg-parsing entry point ; 46: 48C1F803 SAR RAX, 3 ; 4A: 488BD7 MOV RDX, RDI ; 4D: 48C1FA03 SAR RDX, 3 ; 51: 4801D0 ADD RAX, RDX ...
Компилятор «откусил» у аргументов служебные биты и использовал непосредственно машинную операцию сложения. Правда, после сложения компилятор проверяет, вместилось ли получившееся число в тип FIXNUM, или нет. Если не вместилось, то из функции возвращается весьма медленное для последующей обработки число в формате BIGNUM3:
... ; 54: 486BD008 IMUL RDX, RAX, 8 ; 58: 710E JNO L0 ; 5A: 488BD0 MOV RDX, RAX ; 5D: 4C8D1C250C060020 LEA R11, [#x2000060C] ; ALLOC-SIGNED-BIGNUM-IN-RDX ; 65: 41FFD3 CALL R11 ; 68: L0: 488BE5 MOV RSP, RBP ; 6B: F8 CLC ; 6C: 5D POP RBP ; 6D: C3 RET
На этом коротком примере становится понятно, что если от кода требуется максимальная скорость работы, то компилятору лучше подсказывать типы входных аргументов. На практике аргументы функции — это единственное место, где компилятор не может гарантированно вывести типы.
Естественно, не стоит забывать о правиле 20/80 (или даже 10/90), которое гласит, что 20% кода тратят 80% ресурсов процессора, и бросаться декларировать типы по всей программе. Как правило, это излишне, и даже может помешать компилятору выполнить некоторые эффективные преобразования.
Существуют подходы, способные ещё больше улучшить машинный код. Например, если компилятор будет уверен, что при сложении двух целых чисел не произойдёт переполнения типа FIXNUM, то он не будет вставлять финальные проверки результата. Положим, что в функцию будут передаваться только целые числа от нуля до тысячи:
SBCL сгенерировал более оптимальное сложение с использованием одной
единственной команды Load Effective Address (данная техника
описана в официальном документе по оптимизации кода от Intel):
; disassembly for SUM ; 02EB06DB: 488D143B LEA RDX, [RBX+RDI] ; no-arg-parsing entry point ; DF: 488BE5 MOV RSP, RBP ; E2: F8 CLC ; E3: 5D POP RBP ; E4: C3 RET
Компилятор не только убрал проверку типа результата, но ещё и не стал преобразовывать числа из внутреннего формата в машинный. Трюк основан на знании компилятора о том, что для целых чисел в формате FIXNUM служебные биты будут равны нулю, поэтому операцией сложения эти биты не будут искажены.
Измерим время выполнения сложения чисел тремя вариантами функций. Один вызов функции исполняется ничтожно малое время, поэтому воспользуемся сложением в цикле:
Evaluation took: 0.705 seconds of real time 0.700894 seconds of total run time (0.700894 user, 0.000000 system) 99.43% CPU 1,547,423,284 processor cycles 0 bytes consed Evaluation took: 0.592 seconds of real time 0.590910 seconds of total run time (0.590910 user, 0.000000 system) 99.83% CPU 1,298,565,939 processor cycles 0 bytes consed Evaluation took: 0.704 seconds of real time 0.700893 seconds of total run time (0.695894 user, 0.004999 system) 99.57% CPU 1,543,727,900 processor cycles 0 bytes consed
Казалось бы, результат получился странным, т. к. третья, наиболее оптимизированная функция сложения работала со скоростью первой, в которой вообще нет оптимизаций. Такое странное поведение объясняется тем, что компилятор в начале каждой функции по умолчанию вставляет блок проверки количества аргументов и соответствия их типов, если типы в функции были жёстко заданы. Соответственно, для первой функции проверяется только количество аргументов, но не проверяется их тип, т. к. обобщённой функции «+» будут переданы аргументы любых типов. Во второй функции для аргументов делается очень быстрая проверка на тип FIXNUM (это действительно самая быстрая проверка). Для третьей же функции проверяется диапазон значений аргументов, что обуславливает низкую суммарную скорость работы функции.
Так как было решено, что в функцию будут передаваться числа заведомо правильного типа, то можно отключить генерацию проверочного кода, а также включить оптимизацию по скорости. Для этого достаточно определить в самом начале программы декларацию вида:
Документацию по любой конструкции из стандартного языка можно получить на одном из многочисленных зеркал HyperSpec4. Стоит особо отметить, что отключение абсолютно всех проверок безопасности в реальном проекте — очень плохая идея, но в данном случае позволяет продемонстрировать, на что способен SBCL. В крайнем случае, язык позволяет задать флаги оптимизации для одной единственной формы, где эта оптимизация наиболее необходима.
Запустим тест ещё раз:
Evaluation took: 0.670 seconds of real time 0.658900 seconds of total run time (0.658900 user, 0.000000 system) 98.36% CPU 1,470,513,473 processor cycles 0 bytes consed Evaluation took: 0.535 seconds of real time 0.524921 seconds of total run time (0.523921 user, 0.001000 system) 98.13% CPU 1,172,394,883 processor cycles 0 bytes consed Evaluation took: 0.411 seconds of real time 0.404938 seconds of total run time (0.404938 user, 0.000000 system) 98.54% CPU 901,260,173 processor cycles 0 bytes consed
Теперь гораздо лучше: самая оптимизированная функция показала лучший результат. Кроме того, выбор другой политики генерации кода привёл к изменению машинного кода. Наиболее значимое изменение видно в третьем варианте функции, где компилятор использовал одну команду сложения.
; disassembly for SUM3 ; 02DBC24F: 4801FA ADD RDX, RDI ; no-arg-parsing entry point ; 52: 488BE5 MOV RSP, RBP ; 55: F8 CLC ; 56: 5D POP RBP ; 57: C3 RET
С точки зрения процессора команда ADD выполняется по скорости
не хуже, чем LEA, но занимает в памяти на 1 байт меньше.
1.4 Лисп — не медленный
SBCL по качеству генерируемого кода приближается к коду, выдаваемому современными компиляторами Си. Некоторое отставание от них обусловлено тем, что SBCL пока не применяет технику Static Single Assignment, позволяющую устранять избыточное копирование данных и оптимизировать загрузку регистров. Вторым слабым местом является отсутствие поддержки т. н. peephole-оптимизации — архитектурно-зависимой перестановки инструкций для более интенсивной загрузки конвейеров процессора, замены нескольких инструкций на одну, более оптимальную, и др. Впрочем, даже gcc, самый распространённый свободный компилятор Си, научился всем этим хитростям относительно недавно, поэтому стоит ожидать дальнейшего подтягивания SBCL в плане оптимальности кода.
2 Факты, факты...
Не всё гладко в мире функционального программирования, даже если огородить его от нападок адептов Си и производных по синтаксису. Основной фронт противоборства лежит между подходами к типизации в языке. С одной стороны стоят поклонники Haskell, OCaml и других языков со статической типизацией, с другой — Lisp, Smalltalk, Python и прочая «динамика».
Естественной преградой для проведения оптимизаций в динамических
средах является отсутствие информации о типах данных и функций на
этапе компиляции: на вход произвольно взятой функции может прийти
аргумент любого типа, и рантайму языка нужно проверять, допустим ли
данный тип в рамках этой функции, решить, как его нужно обрабатывать.
Например, сложение 32-битных целых отличается от сложения
BIGNUM-чисел, хотя с точки зрения программиста функция для них
применяется одна и та же — полиморфный оператор +.
Но в данный момент нас интересует, скорее, сравнительный материал, наработанный в этом вечном противостоянии: насколько динамически типизируемые языки проигрывают своим статическим собратьям.
2.1 Трассировка лучей
Консалтинговая компания «Flying Frog Consultancy», продвигающая решения на OCaml, провела сравнительное тестирование C++, Haskell, диалектов ML и Lisp. Воспользуемся результатами титанических трудов лучших программистов, и проведём соревнование между постепенно отмирающим, но известным своей хорошей скоростью C++, функциональным Haskell и мультипарадигменными OCaml и Common Lisp.
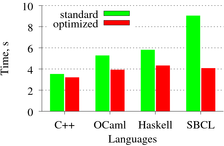
График 1 показывает, что статические Haskell и OCaml работают всего лишь немногим медленнее, чем вариант на более низкоуровневом C++. Динамический SBCL тоже оказался не в сотни раз медленнее, как можно было бы ожидать. Оптимизированная же версия лиспового трейсера даже обогнала Haskell и вплотную приблизилась к OCaml.
Можно смело делать вывод, что для объёмных математических расчётов языки семейства ML являются неплохой альтернативой «плюсам», т. к. предоставляют программисту несравнимо больше возможностей, за которые не приходится платить чересчур высокую цену при выполнении кода.
По мнению автора, оптимизированный вариант трейсера на Лиспе потерял свою лаконичность и стал сложным для понимания. Не говоря уже о том, что такая оптимизация требует чрезмерных усилий даже хорошо подготовленного программиста. Впрочем, серебряных пуль в программировании отливать ещё не научились, и выбор правильного инструмента для решения задачи остаётся одним из самых главных принципов. В данном случае, писать максимально производительный рейтрейсер имеет смысл на другом языке.
2.2 В бой вступают профессионалы
Некоторое время назад к автору обратился его старый знакомый, чтобы автор помог ему со сравнительным тестированием языков. Это не такая грандиозная задача, как уже отмеченные «The Computer Language Benchmarks Game» или трассировка лучей, но интересна она тем, что «сложную» для машинного вычисления задачу сформулировал самый обычный программист, и все реализации делали самые обычные, за пределами своих компаний никому не известные программисты.
Итак, задача состоит в том, чтобы создать N потоков (threads),
сгенерировать в каждом массив из тысячи случайных элементов типа Point
(пары значений x, y типа double, 64-битное число с
плавающей точкой в формате IEEE754), и в двух вложенных циклах
рассчитать квадрат расстояния между точками. На псевдокоде программа
описывается следующим образом:
for a from array.begin to array.end
for b from array.begin to array.end
dx = a.x - b.x
dy = a.y - b.y
result[next] = dx * dx + dy * dy
В тесте принимали участие программы на языках C, C# (Mono), Java, Common Lisp (SBCL) и Erlang. Для того, чтобы гарантированно загрузить двухъядерный процессор, в программах создавалось по 5 потоков. Исходные тексты программ можно найти на сайте журнала.
Результаты тестирования приведены на графике 2.
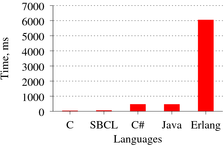
Плохой результат у Erlang связан с не очень быстрым генератором псевдослучайных чисел. При отказе от случайных чисел обсчёт матриц происходит на порядок быстрее, но всё равно понятно, что Erlang для объёмных математических вычислений подходит плохо. Естественно, делать вывод о полной негодности Erlang во всех сферах не стоит, т. к. в том поле, для которого Erlang проектировался, его побить трудно. Да и далеко не все задачи в реальной жизни сводятся к массивной числовой обработке.
Посмотрим ещё раз на тот же график, на этот раз без Erlang (рис. 3). Перед тем, как делать окончательные выводы, хочется ещё раз отметить, что тесты разрабатывались обычными людьми, поэтому могут быть далеки от идеала. Но в целом, результаты получились показательными. Стоить отметить, что в SBCL для генерации псевдослучайных чисел используется весьма дорогой по тактам вихрь Мерсенна, поэтому выигрыш получился не за счёт более «лёгкого» генератора.
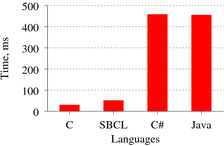
Видно, что языки C# и Java, популярные в софтверных компаниях, оказались в этом «тесте» на порядок медленее SBCL. Конечно, нельзя сказать, что SBCL будет всегда быстрее, чем, например, C#, но нельзя сказать и обратное.
3 Заключение
Надеемся, что миф о страшно медленно работающих программах, как родовом проклятии Лиспа, разрушен.
Учитывая весьма отличающийся подход к разработке программ в Лиспе — модификацию кода и данных «по-живому», без постоянной пересборки бинарного кода — время разработки значительно сокращается. В условиях жёсткой конкуренции на рынке разработки ПО это может принести немалые выгоды.
- 1
- http://shootout.alioth.debian.org/
- 2
- Распространённый диалект Лиспа (не путать с Common Lisp)
- 3
- Формат представления не ограниченных по размеру чисел.
- 4
- HyperSpec — гипертекстовый вариант стандарта языка.
Этот документ был получен из LATEX при помощи HEVEA